
Data lineage is a DAX feature so well-implemented that most developers use it without knowing about its existence. This article describes the data lineage and how it can help producing better DAX code.
Introducing data lineage
First things first, what is the data lineage? Data lineage is a tag, assigned to every column in a table, that identifies the original column of the data model that originated the values of a column. For example, the following query returns the different categories in the Product table:
EVALUATE VALUES ( 'Product'[Category] )
The result contains 8 rows, one for each category:
The table returned by VALUES contains 8 strings. Nevertheless, they are not just strings. DAX knows that these strings originated from the Product[Category] column. Therefore, being columns of the Product table, they inherit the capability of filtering other tables in the model following the filter propagation through relationships. This is the reason why a context transition iterating VALUES ( Product[Category] ) filters the Sales table. Consider the following query:
EVALUATE
ADDCOLUMNS (
VALUES ( 'Product'[Category] ),
"Amt", [Sales Amount]
)
The result of the query includes the value of Sales Amount for each product category:
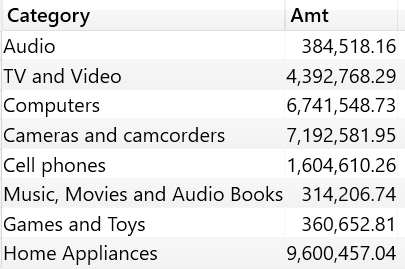
The string “Audio”, by itself, cannot filter Sales. You can easily check this by running the following query:
EVALUATE
VAR Categories =
DATATABLE (
"Category", STRING,
{
{ "Category" },
{ "Audio" },
{ "TV and Video" },
{ "Computers" },
{ "Cameras and camcorders" },
{ "Cell phones" },
{ "Music, Movies and Audio Books" },
{ "Games and Toys" },
{ "Home Appliances" }
}
)
RETURN
ADDCOLUMNS ( Categories, "Amt", [Sales Amount] )
This latter query returns the same value in the Amt column for all the rows:
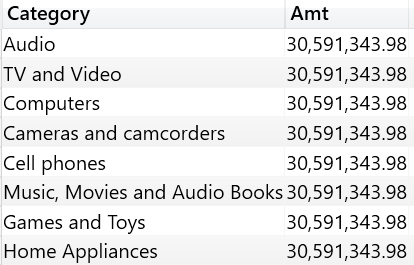
Neither the column name nor the column content are important. What really matters is only the data lineage of a column, which is the original column from where the values have been retrieved. If a column is renamed the data lineage is still maintained. Indeed, the following query returns a different value for every row as:
EVALUATE
ADDCOLUMNS (
SELECTCOLUMNS (
VALUES ( 'Product'[Category] ),
"New name for Category", 'Product'[Category]
),
"Amt", [Sales Amount]
)
The column “New name for Category” still maintains the data lineage of Product[Category]. Therefore, the output shows the sales sliced by category, although the column name in the result is different than the original column name.
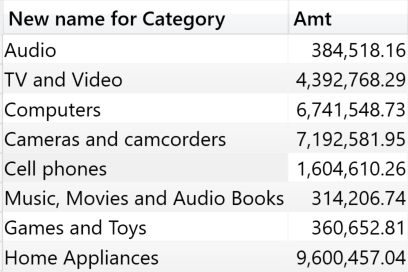
Data lineage is maintained as long as an expression is made by only a column reference. For example, adding an empty string to Product[Category] in the previous expression does not change the column content, whereas it breaks the data lineage. In the following code, the source of New name for Category is an expression instead of only being a column reference. As a result, the new column has a new data lineage that is not related to any of the source columns of the model.
EVALUATE
ADDCOLUMNS (
SELECTCOLUMNS (
VALUES ( 'Product'[Category] ),
"New name for Category", 'Product'[Category] & ""
),
"Amt", [Sales Amount]
)
Unsurprisingly, the result shows the same Amt value for all the rows.
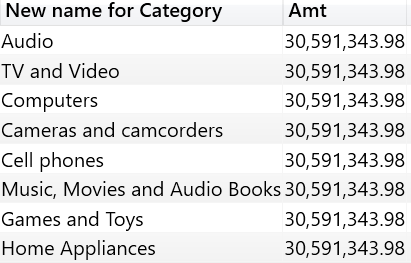
Each column has its own data lineage, even though a table contains columns originated from different tables. Therefore, the result of a table expression can apply filters to multiple tables at once. This is clearly visible in the following query, which contains both Product[Category] and Date[Calendar Year]. Both columns apply their filter to the Sales Amount measure through the filter context originated by context transition.
EVALUATE
FILTER (
ADDCOLUMNS (
CROSSJOIN (
VALUES ( 'Product'[Category] ),
VALUES ( 'Date'[Calendar Year] )
),
"Amt", [Sales Amount]
),
[Amt] > 0
)
The result shows the sales amount for the given category and year. Both columns Category and Calendar Year are actively filtering the Sales Amount measure.
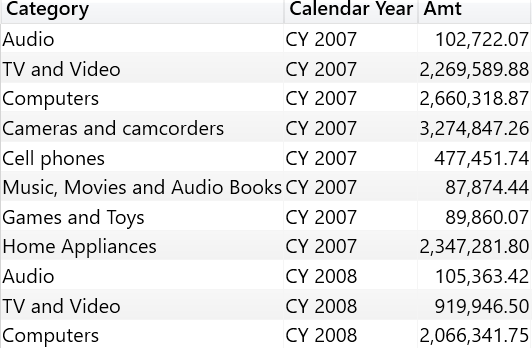
Even though the data lineage is kept and maintained by the engine in a completely automatic way, the developer has the option of changing the data lineage of a table. TREATAS is the function accomplishing this task. TREATAS accepts a table as its first argument, followed by a list of column references. TREATAS returns the same input tables, with each column tagged with the data lineage of the column references specified as arguments. If some of the values in the table contain values that do not correspond to a valid value in the column used to apply the data lineage change, TREATAS removes the values from the input. For example, the following query builds a table with a list of strings, one of which (the highlighted one, “Computers and geeky stuff”) does not correspond to any category in the model. We used TREATAS to force the data lineage of the table to Product[Category].
EVALUATE
VAR Categories =
DATATABLE (
"Category", STRING,
{
{ "Category" },
{ "Audio" },
{ "TV and Video" },
{ "Computers and geeky stuff" },
{ "Cameras and camcorders" },
{ "Cell phones" },
{ "Music, Movies and Audio Books" },
{ "Games and Toys" },
{ "Home Appliances" }
}
)
RETURN
ADDCOLUMNS (
TREATAS (
Categories,
'Product'[Category]
),
"Amt", [Sales Amount]
)
The result contains sales sliced by category, but the row containing Computers and geeky stuff is missing from the output.
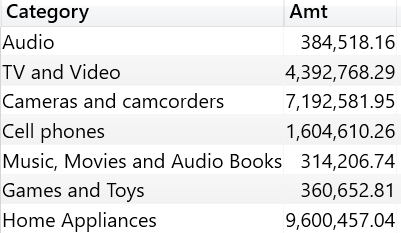
In the data model there is no category named “Computers and geeky stuff”, therefore TREATAS had to remove the row from the output in order to complete the data lineage transformation.
Manipulating data lineage
Now that we saw what the data lineage is and how to manipulate the data lineage by using TREATAS, it is time to see an example where TREATAS and data lineage manipulation produces very elegant DAX code. Consider the requirement of computing the Sales Amount filtering only the first day of sales for each product. The same calculation can be meaningful by customer, by store, or by any other dimension, yet only consider the products in this example.
Each product has a different first-sale date. One option is computing the first date of sales iterating on a product-by-product basis, then compute the Sales Amount in that date and finally aggregate the results for all the products. The following code works just fine:
FirstDaySales v1 :=
SUMX (
'Product',
VAR FirstSale =
CALCULATE (
MIN ( Sales[Order Date] )
)
RETURN
CALCULATE (
[Sales Amount],
'Date'[Date] = FirstSale
)
)
The result produced by the FirstDaySales measure shows a subset of Sales Amount for each Brand.
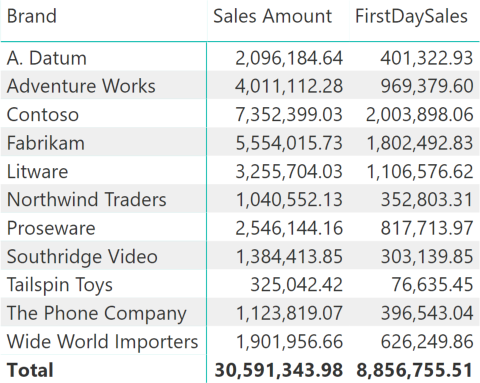
The result is correct, but the code above is not optimal because it iterates the Product table generating a context transition for each product, also applying a filter on Date without leveraging any relationship. Not to say that this is bad code, it is just not as elegant as it could possibly be. We will see alternative versions of this measure trying to obtain the same result in a more efficient way.
A first step in the right direction is building a table containing the product name and the corresponding date of the first sale, then using this pair to apply a filter on Sales. The following code is an improvement compared to the previous one, but it is still non-optimal because SUMX still generates a context transition for each product:
FirstDaySales v2 :=
VAR ProductsWithSales =
SUMMARIZE (
Sales,
'Product'[Product Name]
)
VAR ProductsAndFirstDate =
ADDCOLUMNS (
ProductsWithSales,
"Date First Sale", CALCULATE (
MIN ( Sales[Order Date] )
)
)
VAR Result =
SUMX (
ProductsAndFirstDate,
VAR DateFirstSale = [Date First Sale]
RETURN CALCULATE (
[Sales Amount],
'Date'[Date] = DateFirstSale
)
)
RETURN Result
However, focus your attention on the result of ADDCOLUMNS in the ProductsAndFirstDate variable. It contains a product name and a date. If used as a filter argument of CALCULATE, it will filter a product and a date. Therefore, this version (which is wrong, unfortunately) would be better:
FirstDaySales v3 (wrong) :=
VAR ProductsWithSales =
SUMMARIZE (
Sales,
'Product'[Product Name]
)
VAR ProductsAndFirstDate =
ADDCOLUMNS (
ProductsWithSales,
"Date First Sale", CALCULATE (
MIN ( Sales[Order Date] )
)
)
VAR Result =
CALCULATE (
[Sales Amount],
ProductsAndFirstDate
)
RETURN Result
As you see, the SUMX iteration disappeared from the algorithm. Nevertheless, this version of the code is flawed, because it returns the same value of Sales Amount without applying any filter. Indeed, the result of ADDCOLUMNS in ProductsAndFirstDate contains a product and a date, but from the data lineage point of view the product name is of type Product[Product Name] whereas the date in the First Sales column does not have the data lineage of date, being the result of a MIN expression. The First Sales column has its own data lineage, which is unrelated to the other tables in the data model.
The solution is to change the data lineage of the First Sale column to force it to be Date[Date]. TREATAS exactly exists for this purpose. The correct optimized measure is the following:
FirstDaySales v4 :=
VAR ProductsWithSales =
SUMMARIZE (
Sales,
'Product'[Product Name]
)
VAR ProductsAndFirstDate =
ADDCOLUMNS (
ProductsWithSales,
"First Sale", CALCULATE (
MIN ( Sales[Order Date] )
)
)
VAR ProductsAndFirstDateWithCorrectLineage =
TREATAS (
ProductsAndFirstDate,
'Product'[Product Name],
'Date'[Date]
)
VAR Result =
CALCULATE (
[Sales Amount],
ProductsAndFirstDateWithCorrectLineage
)
RETURN Result
Solutions like this last one do not come to your mind as the first solution of the pattern. Nevertheless, performance-wise this code is nearly optimal, which means that we did not find a better performing version – if you find a better one, we would love to see it in the comments. You start thinking as solutions like the one above once you are acquainted with data lineage, understanding how the filter moves from one table to another one by using data lineage.
Conclusions
In the DAX developer’s toolbelt, understanding data lineage is one important skill. It is not as relevant as row context, filter context and context transition are. Yet, it is for sure one of the skills that distinguish professional DAX developers.